-
[PyTorch] gather 함수 설명(slicing 없이 특정 인덱스만 추출하기)PROGRAMMING/python 2024. 9. 11. 11:17
공식 홈페이지에 나온 torch.gather의 설명은 난해하기 짝이 없다. gather를 이해하려고 여러 포스팅을 읽다가 발견한 명쾌한 영어 설명 https://machinelearningknowledge.ai/how-to-use-torch-gather-function-in-pytorch-with-examples/ & https://medium.com/@mbednarski/understanding-indexing-with-pytorch-gather-33717a84ebc4!! 한국어로 번역해 기록해두면 좋을 것 같아 정리한다.
※ 이 글은 https://machinelearningknowledge.ai/how-to-use-torch-gather-function-in-pytorch-with-examples/ , https://medium.com/@mbednarski/understanding-indexing-with-pytorch-gather-33717a84ebc4를 한국어로 번역한 글입니다. 모든 저작권은 위 포스팅에 있음을 알려드립니다!
Syntax & Parameters
torch.gather(input,dim,index)
- input : The input tensor from which the values have to be gathered
- dim : The dimension of the input tensor along which the elements have to be gathered.
- index: The specific indices along the dimension from where the elements have to be gathered
torch.gather함수는 input의 원소들을 dim기준으로 index에 따라 뽑아서 새로운 Tensor를 만드는 함수다.
여기서 기준이 되는 dim은 우리의 직관과 다르게 움직이는데, PyTorch에서 dim = 0의 의미는 "collapsing" along the row, row를 압축하는 듯한 모양으로 위에서 아래로 움직이며, dim = 1의 의미는 "collapsing" along the column, 즉 왼쪽에서 오른쪽으로의 움직임을 의미한다.
또한 input과 index는 dim 을 제외하고 같은 크기를 가지고 있어야 한다. 예를 들어 input이 4x10x15이고, dim = 0이라면 index는 Nx10x15의 형태만 가능하다.
1D
1차원에서 생각해보자. 이는 우리의 직관과도 매우 일치하는 결과를 가져온다.
import torch tensor1 = torch.arange(10) * 2 # tensor([0, 2, 4, 6, 8, 10, 12, 14, 16, 18]) output = torch.gather(tensor1, 0, torch.tensor([8, 4, 2]) # tensor([16, 8, 4])2D
import torch tensor2 = torch.arange(9).reshape(3, 3) #tensor([[0, 1, 2], # [3, 4, 5], # [6, 7, 8]]) output = torch.gather(tensor2, 0, torch.tensor([0, 1, 2],[2, 1, 0]) #tensor([0, 4, 8], # [6, 4, 2])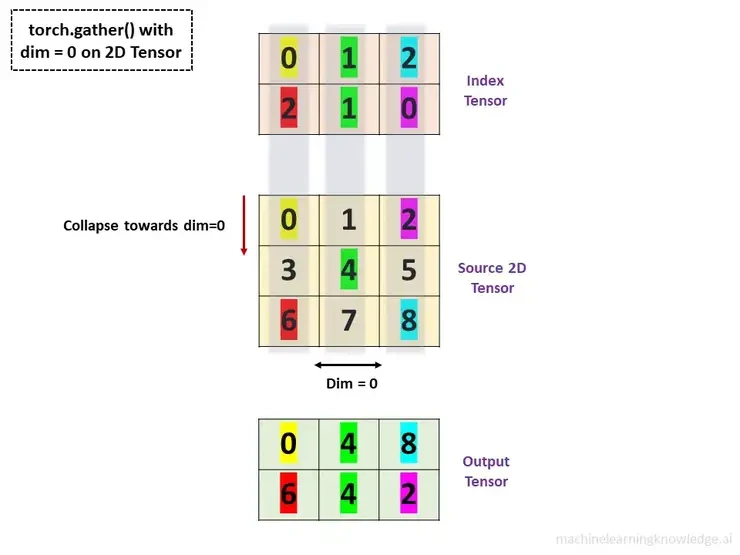
reference : macinelearningknowledge.ai 이 그림이 모든 걸 설명해준다. 정말 직관적이고 아름다운 그림이지 않은가?!
dim = 0이기 때문에 위에서 아래로 내려오면서 index의 각 원소들이 가리키는 자리를 입력 텐서의 인덱스에서 해당하는 값로 선택하면 된다.

reference : macinelearningknowledge.ai 동일한 방법으로 dim = 1인 경우에도 적용해주면 된다. 이렇게 간단할수가!
torch.gather(input=tensor2, dim=1, index = torch.tensor([[2, 1, 0], [0, 2, 1]])) #tensor([[2, 1, 0], # [3, 5, 4]])3D
x를 (batch_size, max_seq_len, hidden_state) = (8, 9, 6)이 되도록 다음과 같이 정의하자.
batch_size = 8 max_seq_len = 9 hidden_size = 6 x = torch.empty(batch_size, max_seq_len, hidden_size) for i in range(batch_size): for j in range(max_seq_len): for k in range(hidden_size): x[i,j,k] = i + j*10 + k*100
x는 다음과 같이 나오는데, 원문의 작성자가 이렇게 x를 지정한 이유는 원소를 보면 i, j, k를 알 수 있기 때문이다. 예를 들어 123은 batch_size = 3, sequence_length = 2, hidden_state = 1임을 알 수 있다.
x[:,4,:] >tensor([[ 40., 140., 240., 340., 440., 540.], [ 41., 141., 241., 341., 441., 541.], [ 42., 142., 242., 342., 442., 542.], [ 43., 143., 243., 343., 443., 543.], [ 44., 144., 244., 344., 444., 544.], [ 45., 145., 245., 345., 445., 545.], [ 46., 146., 246., 346., 446., 546.], [ 47., 147., 247., 347., 447., 547.]])sequence_length = 4로 고정해두면, 1의 자리 숫자인 batch_size는 0에서 7까지, hidden_state는 0에서 6까지 모두 나오는 것을 알 수 있다.
목표 : lens번째 hidden_state 값 추출하기
lens = torch.LongTensor([5,6,1,8,3,7,3,4])sequence length 차원(dim = 1)을 따라 값을 수집할 예정이므로 index의 모양은 8x1x6의 형태를 가지고 있어야 한다.
여기서 핵심은 8개의 값(배치의 각 예제마다 마지막 요소의 인덱스)에 대해 6개의 hidden_state의 값을 수집하는 것이기 때문에 lens를 6번 반복해 8x1x6의 모양을 만들어주면 된다.
⭐ RNN과 같은 시퀀스 기반의 모델에서 sequence_length 차원을 기준으로 값을 수집하는 이유 :
각 sequence는 시간 또는 순차적인 데이터를 나타내고 있으며, hidden_state들이 sequence_length 차원으로 표현된다. sequence length차원을 따라 값을 수집해야 각 시퀀스의 마지막 time step 또는 특정 timestep에서의 hidden_state 값을 추출할 수 있다. RNN은 sequence의 각 단계에서 정보를 처리하며, hidden_state는 각 타임 스텝의 정보를 포함한다.
lens = torch.LongTensor([5, 6, 1, 8, 3, 7, 3, 4]).unsqueeze(-1) indices = lens.repeat(1, 6).unsqueeze(1)이제 dim = 1을 기준으로 gather 함수를 적용해보자.
result = torch.gather(x, 1, indices)결과는 다음과 같이 나온다.


lens = [2, 2, 2, 4, 4, 4, 6, 7]로 수정해서 결과를 시각화하면 다음과 같다.
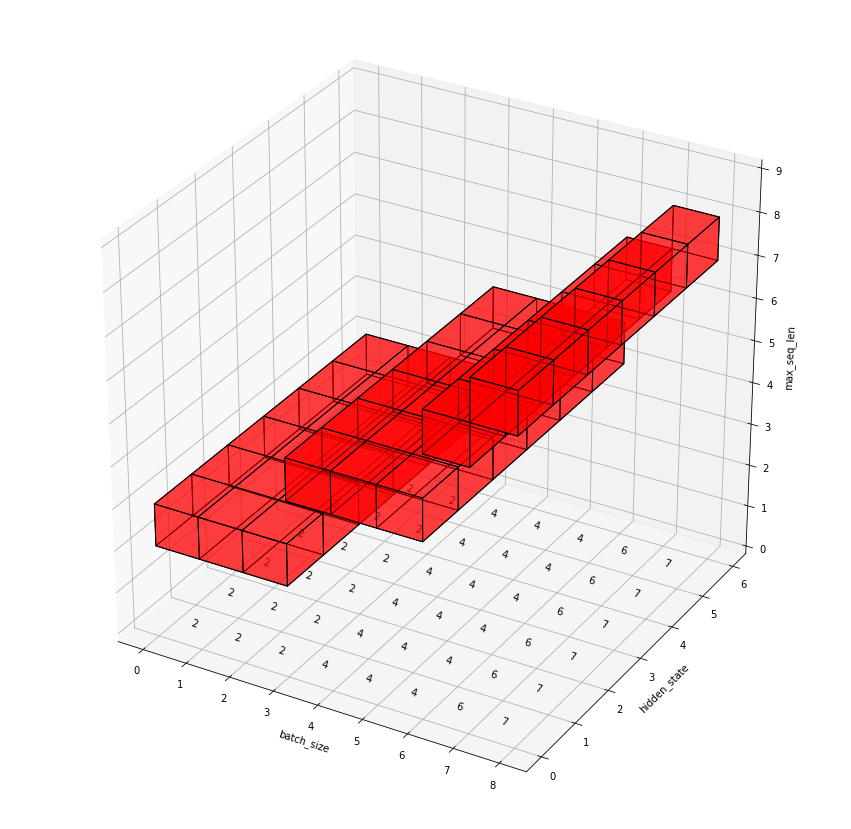
reference : https://medium.com/@mbednarski/understanding-indexing-with-pytorch-gather-33717a84ebc4 reference
[1] https://machinelearningknowledge.ai/how-to-use-torch-gather-function-in-pytorch-with-examples/
[2] https://medium.com/@mbednarski/understanding-indexing-with-pytorch-gather-33717a84ebc4
'PROGRAMMING > python' 카테고리의 다른 글
[1] pykan 라이브러리 사용법 : Hello KAN! (2) 2024.10.13 [GluonTS 3탄] GluonTS로 시계열 데이터 예측해보기 - 심화편 (0) 2024.09.20 [GluonTS 2탄] GluonTS로 시계열 데이터 예측해보기 (1) 2024.09.15 [GluonTS 1탄] GluonTS란 무엇일까? (0) 2024.09.15