-
[GluonTS 2탄] GluonTS로 시계열 데이터 예측해보기PROGRAMMING/python 2024. 9. 15. 21:55
※ 모든 내용은 gluonts 홈페이지에서 번역하여 가져온 내용입니다. 출처는 GluonTS 홈페이지에 있음을 알려드립니다. 번역은 gpt가 했고, 추가로 필요한 부분은 공부해서 채워넣었습니다:)
https://ts.gluon.ai/stable/index.html
GluonTS documentation
Next Installation
ts.gluon.ai
Data set
GluonTS는 다양한 데이터셋을 제공한다. 불러오는 방법은 다음과 같다.
from gluonts.dataset.repository import get_dataset, dataset_names from gluonts.dataset.util import to_pandas print(f"Available datasets: {dataset_names}")GluonTS의 데이터셋은 세 가지 주요 구성 요소로 이루어져 있다.
- train : 모델 학습에 사용되는 데이터셋으로 각 항목은 하나의 시간 시리즈를 나타낸다.
- test : 추론에 사용되는 데이터셋으로 학습 데이터셋의 끝 부분에 훈련 중에 보지 못한 예측창(window)가 포함되어 있다.
- metadata : 데이터셋의 주파수(시간간격), 예측에 권장되는 창의 길이 등 메타데이터를 포함한다.
* 메타데이터(metadata) : 데이터 자체의 속성이나 구조, 정보를 설명하는 데이터
dataset = get_dataset("m4_hourly") entry = next(iter(dataset.train)) train_series = to_pandas(entry) train_series.plot() plt.grid(which = "both") plt.legend(["train series"], loc = "upper left") plt.show()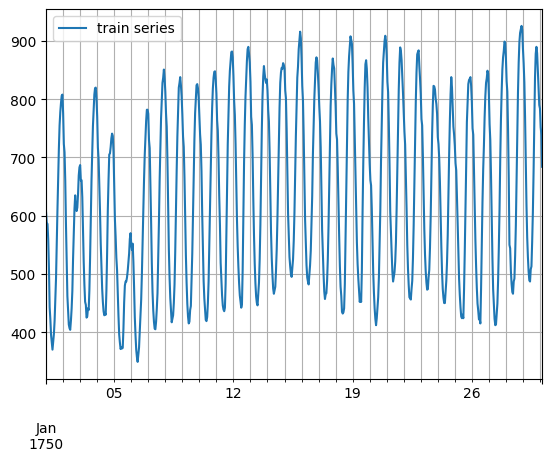 더보기
더보기<부가 설명>
여기서 dataset은 반복 가능한 객체로 gluonts.dataset.common.TrainDatasets이다.
* iter 함수 : 반복 가능한 객체를 이터레이터로 변환
iterator = iter(dataset.train)
>> iter 함수를 사용하면 반복 가능한 객체 dataset.trin에서 항목을 하나씩 순차적으로 가져올 수 있는 이터레이저가 생성
* next 함수 : 이터레이터에서 다음 학목을 가져옴.
entry = next(iterator)
>> iterator에서 첫 번째 항목을 가져온다.
* iter와 next를 함께 사용하는 이유 : 반복 가능한 객체에서 특정 항목을 수동으로 하나씩 가져오고 싶을 때 유
entry = next(iter(dataset.test)) test_series = to_pandas(entry) test_series.plot() plt.grid(which = "both") plt.axvline(train_series.index[-1], color = "r") plt.legend(["test_series", "end of train series"], loc = "upper left") plt.plot()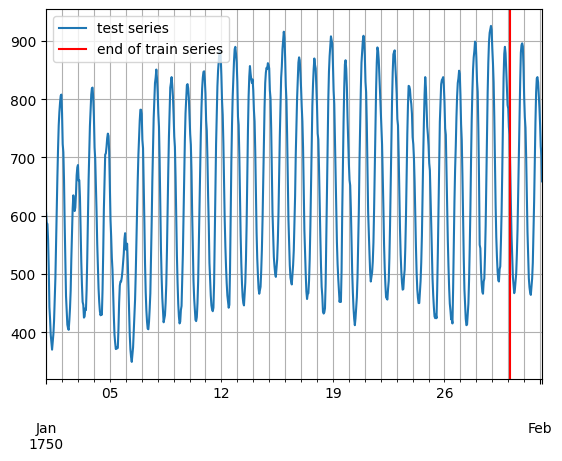
print(f"Length of forecasting window in test dataset: {len(test_series) - len(train_series)}") print(f"Recommended prediction horizon: {dataset.metadata.prediction_length}") print(f"Frequency of the time series: {dataset.metadata.freq}")>>
Length of forecasting window in test dataset : 48
Recommended prediction horizon: 48Frequency of the time series: H
Custom Dataset
GluonTS에서 커스텀 데이터셋을 사용할 때, 반드시 특정한 형식에 맞출 필요는 없다. 필수 조건만 맞추면 되는데 여기서 중요한 두 가지 조건은 다음과 같다.
- 반복 가능(iterable) : 반복적으로 데이터 추출이 가능해야 함
- 각 항목에 target과 start field가 있어야 함 : target은 예측하려는 시간 시리즈의 값이고, start는 그 시간 시리즈가 시작하는 시점을 의미한다.
예시) 10개의 시간 시리즈(N=10)와 100개의 시점(T=100)을 가지는 NumPy배열로 커스텀 데이터셋을 생성하는 과정
N = 10 # 시간 시리즈의 개수 T = 100 # 시간 단계의 개수 prediction_length = 24 # 예측할 창의 길이 freq = "1H" # 1시간 단위로 측정된 데이터 custom_dataset = np.random.normal(size=(N, T)) # 랜덤하게 생성된 데이터셋 start = pd.Period("01-01-2019", freq=freq) # 시작 시점 (각 시간 시리즈가 다를 수도 있음)이 코드는 10개의 시간 시리즈를 랜덤한 값으로 채운 custom_dataset을 생성한다. 시작 시점은 2019년 1월 1일로 설정되어 있으며, 1시간 간격으로 데이터를 측정한 것으로 가정한다.
GluonTS에서는 간단한 코드를 통해 이 데이터를 적절한 형식으로 변환할 수 있다. 아래는 ListDatset 클래스를 사용한 방법이다.
from gluonts.dataset.common import ListDataset # 훈련 데이터셋: 마지막 예측 창 길이만큼의 데이터를 잘라내고, "target"과 "start" 필드를 추가 train_ds = ListDataset( [{"target": x, "start": start} for x in custom_dataset[:, :-prediction_length]], freq=freq, ) # 테스트 데이터셋: 전체 데이터 사용, "target"과 "start" 필드를 추가 test_ds = ListDataset( [{"target": x, "start": start} for x in custom_dataset], freq=freq, )* ListDataset 클래스 : 반복 가능한 형태로 시간 시리즈 데이터를 담을 수 있도록 지원하는 GluonTS의 데이터 구조
더보기데이터셋 관련 gpt 설명
테스트 데이터셋(test_ds)을 만들 때 전체 데이터를 사용하는 이유는 모델이 학습하지 않은 미래의 데이터를 평가하기 위해서입니다. GluonTS에서 테스트 데이터는 모델이 학습한 구간 뒤에 있는 실제 미래 데이터를 포함해야 하므로, 전체 데이터를 사용하여 그 끝부분을 예측하고 평가하는 방식으로 동작합니다.
다음은 더 자세한 설명입니다:
훈련 데이터셋 (train_ds)
훈련 데이터셋은 예측해야 할 **미래 구간(예측 창)**을 제외한 데이터만 사용합니다. 예를 들어, 시계열 데이터가 100개 타임스텝으로 구성되어 있고, 예측 창의 길이가 24개 타임스텝이라면, 훈련 데이터셋에는 처음 76개의 타임스텝만 포함됩니다.
이렇게 하는 이유는 모델이 이 훈련 데이터를 기반으로 패턴을 학습하고, 나머지 예측 창에 대한 값을 예측할 수 있도록 훈련시키기 위해서입니다.
테스트 데이터셋 (test_ds)
테스트 데이터셋에서는 전체 시간 시리즈를 사용합니다. 테스트 데이터셋의 목적은 훈련 데이터셋에서 학습한 모델이 미래의 시점을 얼마나 잘 예측하는지 평가하는 데 있습니다. 훈련된 모델은 테스트 데이터의 **마지막 부분(예측 창)**을 예측하고, 그 예측 결과를 실제 값과 비교하여 성능을 평가합니다.
- 테스트 데이터셋에서 마지막 구간(예측 창)은 모델이 학습하지 않은 구간이므로, 그 부분에 대한 예측을 통해 모델의 성능을 확인할 수 있습니다.
- 예를 들어, 100개의 타임스텝 중 마지막 24개가 예측 창에 해당하면, 모델은 처음 76개 데이터를 기반으로 24개의 예측을 수행하고, 이 예측 결과를 실제 테스트 데이터셋의 마지막 24개 값과 비교해 평가하게 됩니다.
Training an existing model(Estimator)
GluonTS는 여러 개의 사전 구축된 모델을 제공하므로 사용자는 몇 가지 하이퍼파라미터만 구성하면 된다. 이 예시에서는 Simple Feed Forward Estimator모델을 사용해보자.
GluonTS의 Simple Feed Forward Estimator은 context_length 길이의 입력 창(window)를 받아 이후 prediction_length 값의 분포를 예측한다. GluonTS에서는 Feed forward network model이 Estimator의 한 예시로, Estimator 객체는 예측 모델을 나타내며, 그 안에 모델의 계수, 가중치 등 세부 정보가 포함된다.
Estimator는 여러 하이퍼파라미터로 구성되며, 모든 Estimator에 공통적으로 사용할 수 있는 하이퍼파라미터도 있지만(예 : prediction_length), 특정 Estimator에서만 사용하는 파라미터 일 수도 있다.
각 Estimator는 Trainer로 구성되며, 이는 모델이 에포크 수, 학습률 등 모델이 어떻게 학습될지를 정의한다.
from gluonts.mx import SimpleFeedForwardEstimator, Trainer estimator = SimpleFeedForwardEstimator( num_hidden_dimensions=[10], prediction_length=dataset.metadata.prediction_length, context_length=100, trainer=Trainer(ctx="cpu", epochs=5, learning_rate=1e-3, num_batches_per_epoch=100), )필요한 모든 하이퍼파라미터를 지정한 후, train 매서드를 사용하여 학습 데이터셋 dataset.train을 사용하여 모델을 훈련할 수 있다. 학습 알고리즘은 학습된 모델(또는 GluonTS에서는 Predictor라고 부르는 객체)을 반환하며, 이를 사용해 예측을 생성할 수 있다. 훈련 과정은 각 에포크의 평균 손실 값을 출력한다.
* gluonts.mx : GluonTS 라이브버리에서 MXNet 딥러닝 프레임 워크를 기반으로 하는 모듈. MXNet을 백엔드로 사용하는 GluonTS 모델을 정의하고 학습할 때 사용한다.
* GluonTS에서느 MXNet 기반이 아닌 Pytorch 기반 모델을 사용할 때는 PyTorch 전용 Trainer는 따로 없으므로 PyTorch의 기본 학습 루프나 PyTorch Lightning 같은 패키지를 사용해 학습한다.
⚠️ GluonTS나 mxnet에서 np.bool을 사용하고 있어 버전 문제가 발생한다.... ㅠㅠ numpy의 버전을 낮추면 해결이 될 것 같은데,, 말처럼 잘 작동하지 않는다. ㅎㅎ
predictor = estimator.train(dataset.train)이 아래 실험은 numpy와 GluonTS의 버전 문제로 직접 진행하지는 못하고, 홈페이지를 그대로 가져왔다.
Visualize and evaluate forecasts
모델 학습을 마치고 나면, 이제 dataset.test의 마지막 구간을 예측하고 모델의 성능을 평가할 수 있다.
GluonTS에서는 make_evaluation_predictions 함수가 있어 예측 및 모델 평가 과정을 자동화할 수 있다. 이 함수는 다음과 같은 단계를 수행한다.
- 예측하려는 구간의 길이만큼 dataset.test의 마지막 부분을 제거한다.
- Estimator는 남은 데이터를 사용해, 방금 제거된 "미래" 구간을 샘플 경로 형태로 예측한다.
- 이 모듈은 예측 샘플 경로와 dataset.test를 Python generator객체로 출력한다.
* python generator에 대하여)
더보기* python generator 객체 : 일반적인 리스트나 튜플과 다르게, 한 번에 하나의 항목을 생성하고 반환하는 객체로 데이터를 한꺼번에 메모리에 저장하지 않고, 필요할 때마다 하나씩 계산하고 반환하는 방식으로 동작한다.
* generator의 특징
(1) 메모리 효율성
(2) 지연 평가 : 실제로 값이 필요할 때만 계산
(3) next()로 값 접근 : for 루프 또는 next()함수를 사용해 한 번에 하나씩 순차적으로 값을 가져옴
* generator 만드는 방법
- generator 함수 : yield 키워드를 사용해 정의
- generator 표현식 : list comprehension과 유사한 방식으로 간단한 generator 만들 수 있음
def simple_generator(): yield 1 yield 2 yield 3 gen = simple_generator() # 제너레이터 객체 생성 print(next(gen)) # 1 출력 print(next(gen)) # 2 출력 print(next(gen)) # 3 출력여기서 yield는 함수가 반환될 값을 지정하면서 실행 상태를 멈추고, 이후 next() 호출 시 다시 실행 상태를 이어간다.
from gluonts.evaluation import make_evaluation_predictions forecast_it, ts_it = make_evaluation_predictions( dataset=dataset.test, # 테스트 데이터셋 predictor=predictor, # 예측기 num_samples=100, # 평가를 위해 생성할 샘플 경로 수 )이후의 계산을 쉽게 하기 위해 제너레이터를 리스트로 반환한다.
forecasts = list(forecast_it) tss = list(ts_it)우선 tss의 요소를 확인해보자. tss의 첫번째 항목은 dataset.test의 첫 번째 시간 시리즈의 목표값(target)을 포함할 것이다.
# 시간 시리즈 리스트의 첫 번째 항목 ts_entry = tss[0] # 시간 시리즈의 첫 5개의 값 (pandas에서 numpy로 변환) np.array(ts_entry[:5]).reshape(-1,) >> array([605., 586., 586., 559., 511.], dtype=float32)# dataset.test의 첫 번째 항목 dataset_test_entry = next(iter(dataset.test)) # 첫 5개의 값 dataset_test_entry["target"][:5] >> array([605., 586., 586., 559., 511.], dtype=float32)forecast 리스트 항목은 tss보다 조금 더 복잡하다. 이들은 numpy.ndarray 형태로 모든 샘플 경로를 포함하고 있으며, 샘플 경로의 차원은 (num_samples, prediciton_length)이다. 이 외에도 예측의 시작 날짜, 시간 시리즈의 주기(frequency)등을 포함하고 있다. 이러한 정보는 해당 예측 객체의 속성으로 접근할 수 있다.
# 예측 리스트의 첫 번째 항목 forecast_entry = forecasts[0] print(f"샘플 경로 수: {forecast_entry.num_samples}") print(f"샘플의 차원: {forecast_entry.samples.shape}") print(f"예측 창의 시작 날짜: {forecast_entry.start_date}") print(f"시간 시리즈의 주기: {forecast_entry.freq}") >>샘플 경로 수: 100 >>샘플의 차원: (100, 48) >>예측 창의 시작 날짜: 1750-01-30 04:00 >>시간 시리즈의 주기: <Hour>각 48개의 시간 구간에 대한 샘플 경로의 평균 또는 분위수를 계산하여 요약할 수도 있다.
print(f"미래 창의 평균:\n {forecast_entry.mean}") print(f"0.5 분위수(중앙값) 미래 창:\n {forecast_entry.quantile(0.5)}") >>미래 창의 평균: [639.66077 658.0511 552.81476 533.2969 493.03867 497.4587 388.23367 508.86005 488.38263 585.7019 590.5804 633.5566 735.9546 818.53827 827.5405 896.6119 881.3922 831.70624 836.5081 806.9725 768.7379 770.90674 725.0249 709.9852 621.17413 587.09485 535.24194 496.24234 474.26944 523.7688 538.42224 492.28284 497.149 570.52 639.18506 728.5694 844.8908 842.5762 857.1248 895.1651 911.2351 934.3844 881.88776 888.31445 887.12085 797.9183 742.78937 698.47845] 0.5 분위수(중앙값) 미래 창: [651.8985 655.4397 566.98926 542.85333 485.50317 492.54675 403.92365 513.5063 496.67416 565.9679 585.32837 631.4199 753.55536 828.24176 829.8248 911.32104 861.32385 828.74243 830.79584 812.5209 767.35565 762.20795 720.6565 692.8951 614.735 589.99115 536.9734 501.07224 474.88385 512.0502 522.1414 484.35178 492.1236 578.683 640.3349 717.25037 825.409 858.3357 853.95703 910.81256 890.8249 946.8613 893.7431 866.7187 860.7763 803.37836 753.6842 708.0245 ]예측 객체에는 예측 경로를 평균, 예측 구간(신뢰 구간)등으로 요약하는 plot 매서드가 있다. 예측 구간은 서로 다른 색상으로 음영 처리되는 팬 차트(fan chart)로 나타난다.
plt.plot(ts_entry[-150:].to_timestamp()) forecast_entry.plot(show_label=True) plt.legend()
GluonTS에서는 Evaluator 클래스를 사용해 성능 지표를 계산할 수 있다. 이는 전체 시간 시리즈에 대한 성능 지표와 각 시간 시리즈별 성능 지표를 제공한다.
from gluonts.evaluation import Evaluator evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9]) agg_metrics, item_metrics = evaluator(tss, forecasts)전체 시간 구간(across time-steps)과 전체 시간 시리즈(across time series)에 대한 집계 지표는 agg_metrics에 저장된다.
print(json.dumps(agg_metrics, indent=4)) >>{ "MSE": 10330287.941363767, "abs_error": 9888776.191505432, "abs_target_sum": 145558863.59960938, "abs_target_mean": 7324.822041043146, "seasonal_error": 336.9046924038305, "MASE": 3.298529737437924, "MAPE": 0.24230639967653486, "sMAPE": 0.1844004778050474, "MSIS": 64.15294911907903, "num_masked_target_values": 0.0, "QuantileLoss[0.1]": 4685229.677179908, "Coverage[0.1]": 0.10487117552334944, "QuantileLoss[0.5]": 9888776.174993515, "Coverage[0.5]": 0.5401066827697263, "QuantileLoss[0.9]": 7182032.328086851, "Coverage[0.9]": 0.8878824476650563, "RMSE": 3214.076530103751, "NRMSE": 0.4387924392011613, "ND": 0.06793661304409888, "wQuantileLoss[0.1]": 0.032187869301230805, "wQuantileLoss[0.5]": 0.0679366129306608, "wQuantileLoss[0.9]": 0.04934108545833773, "mean_absolute_QuantileLoss": 7252012.726753425, "mean_wQuantileLoss": 0.049821855896743115, "MAE_Coverage": 0.39596081588835214, "OWA": NaN }각 시간 시리즈에 대한 개별 성능 지표는 item_metrics에 저장되며, 이를 시각화할 수 있다.
item_metrics.head()item_metrics.plot(x="MSIS", y="MASE", kind="scatter") plt.grid(which="both") plt.show()
원문 : https://ts.gluon.ai/stable/tutorials/forecasting/quick_start_tutorial.html
'PROGRAMMING > python' 카테고리의 다른 글
[1] pykan 라이브러리 사용법 : Hello KAN! (3) 2024.10.13 [GluonTS 3탄] GluonTS로 시계열 데이터 예측해보기 - 심화편 (0) 2024.09.20 [GluonTS 1탄] GluonTS란 무엇일까? (0) 2024.09.15 [PyTorch] gather 함수 설명(slicing 없이 특정 인덱스만 추출하기) (1) 2024.09.11