-
CS236 3장 Autoregressive Models 정리PROGRAMMING/머신러닝 2024. 6. 12. 16:02
Generative model 복습을 위해 CS236 강의를 듣고 정리해보고자 한다.
피피티는 아래 페이지를 참고하면 된다.
https://deepgenerativemodels.github.io/
Stanford University CS236: Deep Generative Models
Course Description Generative models are widely used in many subfields of AI and Machine Learning. Recent advances in parameterizing these models using deep neural networks, combined with progress in stochastic optimization methods, have enabled scalable m
deepgenerativemodels.github.io
※ PPT의 내용 정리와 더불어 같이 보면 좋을 자료들을 정리했습니다. 강의를 보고 이해한대로 작성했기 때문에 부정확한 내용이 포함되어 있을 수 있음을 알려드립니다.
Learning a generative model
우리의 목표는 이미지의 probability distribution $p(x)$를 학습해서 다음과 같이 다양한 활동을 할 수 있다.
1. Generation(새로운 이미지를 생성하고)
2. Density estimation(학습한 분포를 통해 판별하고 - anomaly detection)
3. Unsupervised representation learning(features들에 대해서도 학습)
그렇다면 우리는 probability distribution $p(x)$를 어떻게 나타내며, 학습해야할까?

Recap : Bayesian networks vs neural models
2장에서 언급한대로 우리는 multivariate probability distribution을 Chain Rule, Bayesian network, neural network를 통해 나타낼 수 있다.
1. Chain Rule : 가정이 필요 없으나 지나치게 복잡
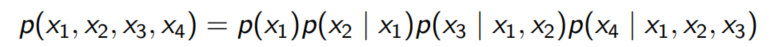
2. Bayesian Network : 조건부 독립을 가정하며, 모델 feature들의 관계를 통해 파악해야 함
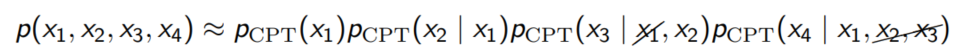
3. Neural Network : 상당히 깊은 neural networ를 통해 거의 모든 함수를 근사할 수 있다는 점을 이용해 표현

MNIST 학습하기
※ MNIST는 딥러닝에서 매우 유명한 손으로 쓴 숫자 그림 셋으로 0부터 9의 손글씨를 분류해야 하는 classification 문제에서 단골로 나오는 데이터 셋이다.
각 이미지의 크기가 28 X 28 = 784 인 MINIST 셋을 학습한다고 하자.
GOAL : 손글씨를 나타내는 확률변수 X의 확률밀도함수 $p(x) = p(x_1, ..., x_{784})$ , $ x \in {0, 1}^784$ 학습
이 강의에서는 ${p_{\theta}(x), \theta \in \Theta}$의 파라미터를 학습하고자 한다.
여기서 우리가 고려해 볼 수 있는 모델은 Autoregressive Models, FVSBN(Fully Visible Sigmoid Belief Network), NADE(Neural Autoregressive Density Estimation), RNADE(Real-valued NADE), Autoencoder, MADE(Masked Autoencoder for Distribution Estimation), RNN 등이 있다.
1. Autoregressive Models
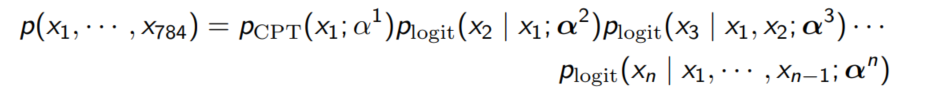

Autoregressive Model은 현재 노드가 결정될 확률$p(x_t)$를 이전 노드들 $x_1, x_2, ..., x_{t-1}$ 에 대한 선형 결합으로 적을 수 있다는 가정이다.
손글씨이기 때문에 현재의 픽셀은 과거의 모든 픽셀에 영향을 받는다는 아이디어에서 적용해봄직한 모델이다.
※ 과거 공부자료 참고
2. Fully Visible Sigmoid Belief Network(FVSBN)
이진 데이터 모델링에 주로 사용되는 네트워크로 주로 각 노드가 이전 노드들의 값에 기반해여 sigmoid 함수를 통해 활성화된다는 모형이다.
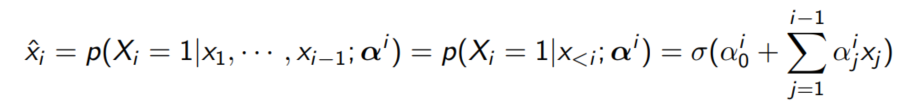
$x_1$에 대해 1개의 파라미터가, $x_2$에 대해 2개의 파라미터가, ..., $x_n$에 대해 n개의 파라미터가 필요하므로 대략 $ \frac{n^2}{2}$개의 파라미터가 필요하다. 노드의 수가 늘어가면 필요한 파라미터의 수가 급격히 늘어나므로 과적합(overfitting)할 가능성이 커지는 모델이다.
그리고 실제로 이 모델을 통해 학습한 결과 역시 그닥 좋지 않다는 점을 강의에서 예시를 통해 보여주고 있다.

3. NADE(Neural Autoregressive Density Estimation)
앞서 FVSBN가 현재 노드를 과거 노드들의 선형결합을 sigmoid 함수를 통해 나타냈다면, NADE에서는 여기에 한 개의 neural layer를 추가해 모델을 발전시켰다.

FVSBN에서는 matrix A 대신 scalar 값을 사용 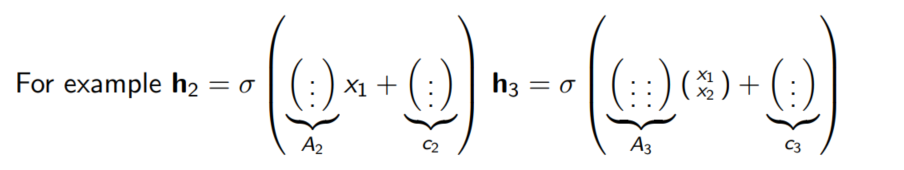
다만 $A_i$ 행렬을 사용할 경우 파라미터의 수가 너무 많아지기 때문에 계산의 간편함을 위해 앞에서 사용한 행렬을 다시 사용하도록 모델을 간소화할 수 있다. 파라미터의 수를 줄이면서 과적합을 방지할 수 있으며, 비교적 적은 수의 파라미터로 고차원의 데이터를 효과적으로 처리할 수 있다.
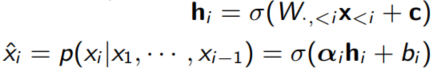
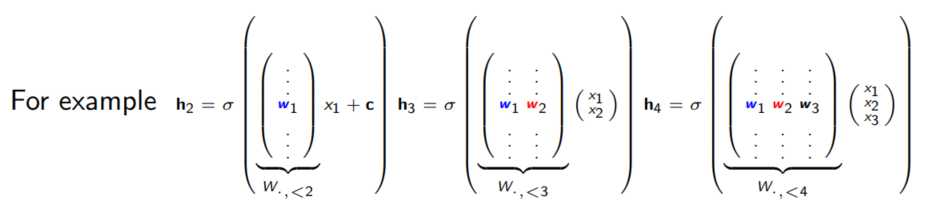
이때 파라미터의 갯수는 matrix W의 크기를 d X n이라고 했을 때, 변향 c벡터와 $\alpha$, $\beta$가 d차원이므로 $O(nd)$가 된다.
NADE는 FVSBN에 비해 상당히 성공할 결과를 강의에서 보여주고 있다.

참고로 categorical distribution을 구할 때는 마지막에 sigmoid 함수 대신 softmax 함수를 사용하면 된다.
4. RNADE(Real-valued Neural Autoregressive Density estimator)
RNADE는 NADE 모델에서 연속 데이터를 다룰 수 있도록 확장한 모델로 각 차원의 값 $x_i$를 조건부 확률 분포를 사용해 모델링한다.
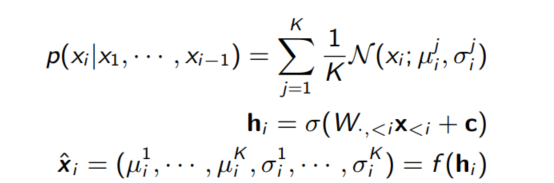
이전 차원의 값에 기반하여 $\hat{x_i}$를 통해 K개의 평균과 분포를 결정하는 방식으로 분포를 결정한다.
5. Autoencoder
※ 강의 내용에 Autoencoder는 잘 담겨있지 않아 신박Ai님의 오토인코더 소개 영상을 참고해 정리해보았다.
https://www.youtube.com/watch?v=T97B4h709m4
오토인코터는 비지도학습의 일종으로 데이터에서 중요한 신경을 추출하고 압축(encoder)한 후 다시 복원(decoder)하는 과정을 거치게 된다. decoder 부분은 latent layer에서 이미지를 생성하도록 하고 있어 generative model로 사용이 가능하다.
6. MADE(Maksed Autoencoder for Distiribution Estimation)
Autoencoder 역시 DAG(Directed acyclic graph) structure를 가지고 있으며, 입력 노드들이 각각의 layer에 모두 영향을 주기 때문에 변수 간의 의존성이 생길 수 있다. 이를 방지하기 위해 MADE가 제시되었으며, MADE는 전통적인 Autoencoder 구조에 특수한 마스킹을 적용하여 입력 데이터의 부분집합을 제한하도록 한다.
7. RNN(Recurrent Neural Networks)
※ 강의 내용에 RNN이 잘 담기지 않아 허민석님 RNN 기초 영상을 참고했다.
https://www.youtube.com/watch?v=PahF2hZM6cs
순차적 데이터나 시계열 데이터 처리에 특화된 신경망 구조로 현재 상태의 입력과 함께 이전 단계의 출력을 함께 처리해서 현재 상태의 출력을 만들어 낸다.
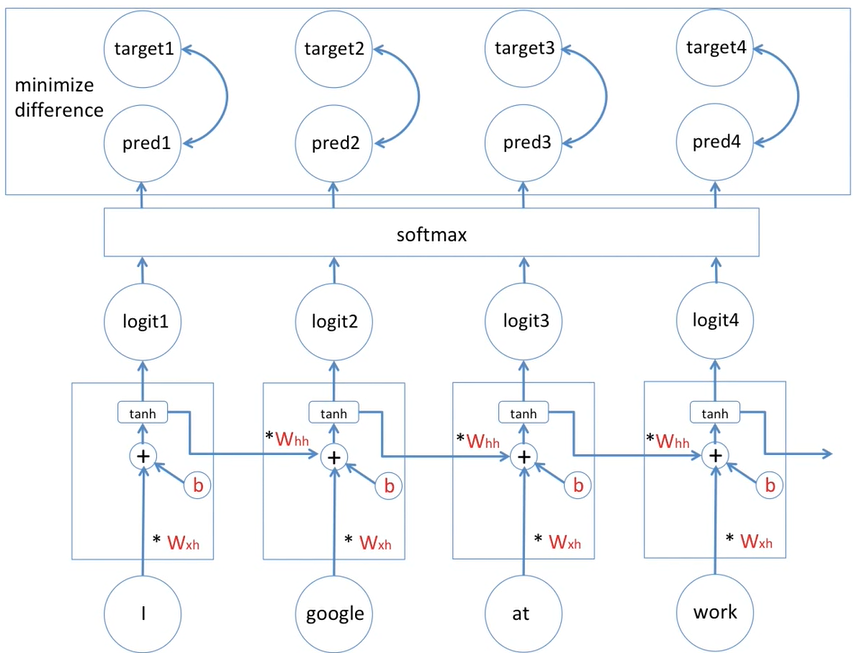
출처 : https://www.youtube.com/watch?v=PahF2hZM6cs 참고로 여기서는 동일한 변수를 사용하기 때문에 backpropagation이라 칭하지 않고 back propagation through time(bptt)이라고 부른다.
동일한 파라미터를 사용하기 때문에 일반화 능력이 상승하지만, 긴 시퀀스를 처리할 때 gradient vanishing / explosion 문제가 발생할 수 있고, 순차적으로 계산하기 때문에 느리고 병렬 처리가 어렵다는 단점이 있다.
또한 하나의 out이 과거의 모든 자료 특징을 모두 가지고 있어야 하므로 잘 작동하지 않을 수 있다.
8. Attention based models
RNN은 마지막 노드의 모든 과거 자료가 응집되기 때문에 퍼포먼스에 한계가 있다는 문제점을 가지고 있었다. 이를 극복하기 위해 Attetion 매커니즘에서는 과거의 자료를 하나의 output으로 응집하는 대신, 각 과거의 자료를 현재 노드 학습에 활용한다. 이때 현재의 hidden state를 Query, 과거의 모든 hidden states를 Key라고 부른다.
1. Query : the current hidden state of a model
2. Key : all past hidden states
Attention의 매커니즘은 다음과 같은 순서로 진행된다.
1. Query를 key들과 비교(compare)한다.(내적 등을 통해 key의 값을 반영한 Query의 값을 구하자)
2. attention distribution을 만들고 현재의 노드가 과거 어떤 부분이랑 관련이 큰 지 확인한다.
3. 과거 값을 모두 반영한 hidden state를 만들고(가중치는 attention probability 사용)
4. 다음 단어를 추정한다.
9. Pixel RNN(Row LSTM & Diagonal BiLSTM) & Pixcel CNN
Pixel RNN은 Jaejun Yoo님의 픽셀 순환 신경망 영상을 참고했습니다.
https://www.youtube.com/watch?v=BvcwEz4VPIQ
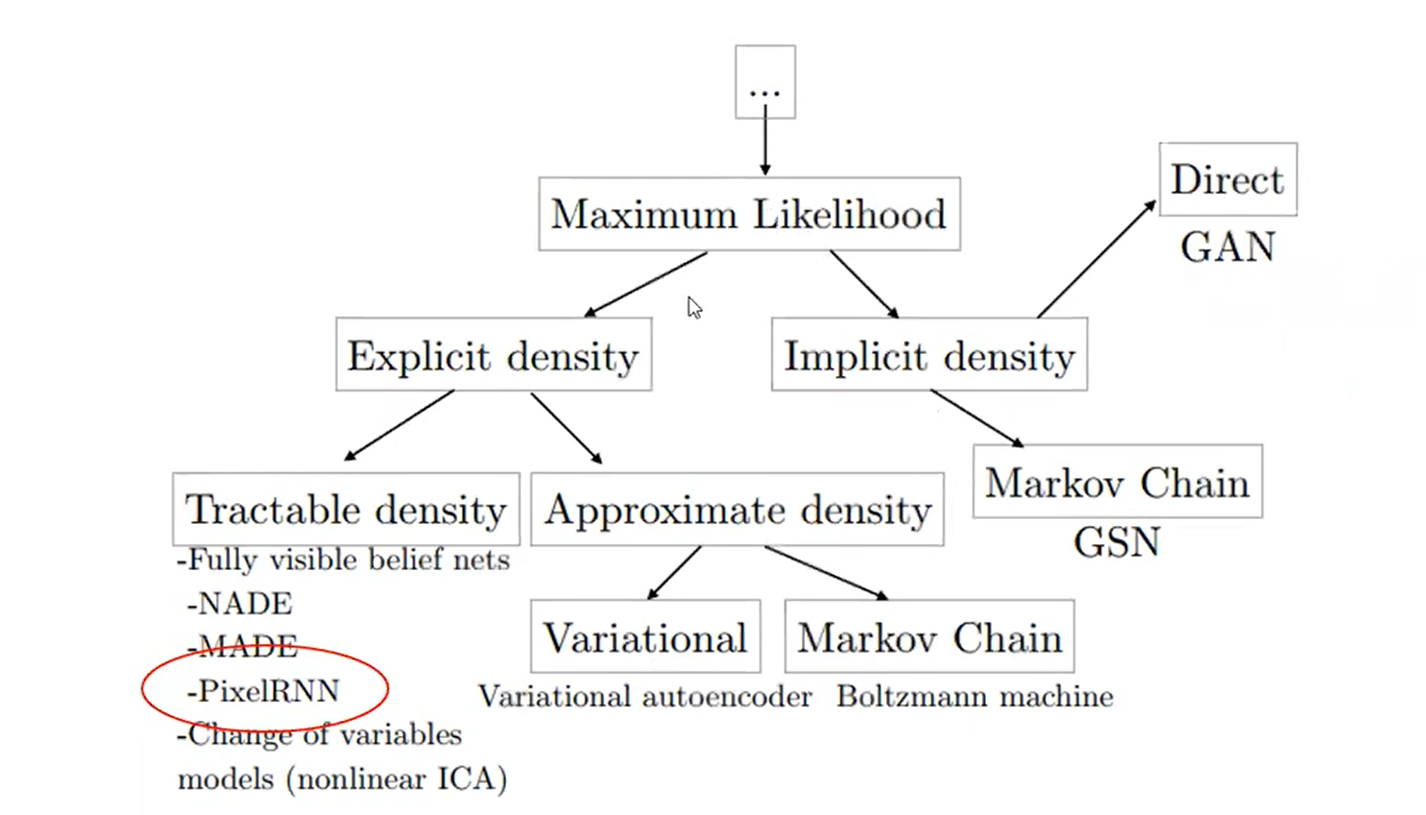

Pixel RNN : Autoregressive Models의 일종으로 latent variable이 없기 때문에 tractable하고, 학습이 쉽다는 특징이 있다. Wavenet의 근간이 되는 페이퍼이며, 추가 관련 페이퍼로는 GRAN이 있다.
11. WaveNet
Wavenet 내용은 아래 좋은 블로그가 있어 소개한다.
https://joungheekim.github.io/2020/09/17/paper-review/
Summary of Autoregressive Models
Autoregressive Model은 샘플링하고, probability를 계산하거나 continuoes variable로 확장하는 것이 쉽지만, feature를 추출하거나 비지도 학습을 하기 부적합하다는 특징도 가지고 있다.
'PROGRAMMING > 머신러닝' 카테고리의 다른 글
cs236 5-6장 Latent Variable Models(VAEs) (0) 2024.06.20 Importance Sampling(중요도 샘플링) (0) 2024.06.19 CS236 4장 Maximum Likelihood Learning (0) 2024.06.14