-
DDIM 논문 리뷰(Denoising Diffusion Implicit Models)논문 리뷰/Generative Model 2024. 8. 13. 19:13
DDPM와 함께 매우 유명한 논문으로 알려진 DDIM에 대해 리뷰해보고자 한다.
※ DDPM 논문 리뷰 포스팅은 이 포스팅을 참고하면 된다.
DDIM과 DDPM의 차이점
(1) DDPM의 forward process는 markovian이지만 DDIM의 forward process는 non-markovian이다.
(2) DDPM의 backward process는 stochastic하지만 DDIM의 backward process는 deterministic하다.
(그래서 DDIM의 샘플은 일종의 "consistency"를 가지고 있어 같은 initial latent variable로 시작했을 때 비슷한 모습의 샘플을 생성하며, 의미있는 보간된 이미지 또한 생성한다.)
DDIM은 (1) 동일한 퀄리티의 샘플을 생성하는 것이 DDPM보다 몇 십배 빠르며, (2) sematically meaningful image interpolation을 가능하게 하고 (3) reconstruction error가 매우 작다.
Introduction
DDPM의 가장 큰 단점은 좋은 퀄리티의 샘플을 얻기 위해 매우 많은 iteration이 필요하다는 점이다. Diffusion model은 GAN과 비교했을 때 수십만배 느리다는 사실을 알 수 있는데, 고해상도 사진을 생성하는데 있어 diffusion model은 생성 속도가 큰 문제이다. 이러한 문제를 완화하고자 이 논문에서는 Denoising Diffusion Implicit Models(이하 DDIM)을 제안한다. DDIMs은 일종의 implicit probabilistic model로 DDPM과 objective function을 공유한다는 점에서 공통점을 가지고 있다.
우리는 앞으로 DDPM의 Markovian인 forward diffusion process를 non-Markovian으로 확장시키면서도 적절한 reverse generative Markov chain을 정의할 것이다. 이 때 목적함수는 DDPM과 정확히 동일할 것이며, 이를 통해 좀 더 "짧은" generative Markov chain을 얻을 것이다.
Background
데이터 분포 $q(x_0)$에 대해 우리는 모델 분포 $p_{\theta}(x_0)$가 $q(x_0)$를 학습하기를 바란다. DDPM에서는 laten variables $x_1, ..., x_T$의 models을 다음과 같이 정의한다.

파라미터 $\theta$는 아래 variational lower bound를 최대화 하는 방향으로 학습된다.
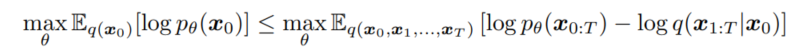
DDPM은 다른 모델과 달리 fixed inference procedure $q(x_{1:T}|x_0)$를 가지고 있으며, 다음의 Markov chain with Gaussian transitions로 정의된다. 여기서 $alpha_{1:T}$는 decreasing sequence로 학습 대상이 아니다.

우리는 위 과정(from $x_0$ to $x_T$)을 forward process라고 부른다. 또한 latent variable model $p_{\theta}(x_{0:T})$를 generative process라고 부른다. 직관적으로 forward process는 데이터에 noise를 추가하는 과정을, generative process는 noise로부터 denoise하는 과정으로 생각할 수 있다.
forward process는 Markovian이므로 다음과 같은 특징을 가지고 있다.

따라서 우리는 $x_t$를 다음과 같이 쓸 수 있다.

여기서 우리는 ${\alpha}_T$를 0에 가깝게 골라 $q(x_T|x_0)$가 standard Gaussian이 되도록 할 수 있다. 따라서 $p_{\theta}(x_T) := N(0, I)$로 두는 것이 자연스럽다. 또한 DDPM 논문에 의해 objective는 다음과 같이 구할 수 있다.

DDPM 논문에는 $\gamma = 1$로 설정하여 objective function $L_1$을 최적화하였으며, $T$의 길이는 $1000$으로 설정하였다. 참고로 DDPM에서는 1000번의 iteration을 sequential하게 진행했으므로 상당히 느리다.
Variational inference for non-markovian forward process
Our key observation is that the DDPM objective in the form of $L_{\gamma}$ only depends on the marginals $q(x_t|x_0)$, but not directly on the joint $q(x_{1:T}|x_0)$.
생성 모델이 추론 과정의 역과정을 근사해야 하기 때문에 DDIM에서는 생성 모델의 반복횟수를 줄이기 위해 노력했다. DDPM의 objective에서 중요한 점은 $L_{\gamma}$가 marginals에 의존하고, joint에는 의존하지 않는다는 것이다. 이에 DDIM에서는 non-Markovian inference process를 새롭게 고안하여 DDPM과 같은 objective function은 공유하면서도 interence process를 새롭게 하였다.
inference distribution을 다음과 같이 정의하자. 아래와 같이 정의하면 forward process는 더이상 Markovian이 아니다.

위 식에서 $\sigma$의 역할이 상당히 중요한데, $\sigma$의 크기가 forward process가 얼마나 stochastic한지를 결정한다. 만약 $\sigma$가 0으로 수렴한 경우를 생각해본다면 우리에게 $x_0$와 $x_t$가 주어졌을 때 $x_{t-1}$을 deterministic하게 알 수 있다.
이제 generative process에 대해 생각해보자.

참고로 위에서도 언급했는데, $x_0$와 ${\epsilon}_t$가 주어졌을 때 $x_t$는 다음과 같이 쓸 수 있다.
모델 ${\epsilon}_{\theta}^{(t)(x_t)}는 $x_0$는 주어져 있지 않고, $x_t$가 주어졌을 때의 ${\epsilon}_t$를 예측한다. 위 식을 다시 작성하면 노이즈가 제거된 관측값($x_t$가 주어졌을 때의 $x_0$)을 예측할 수 있다.
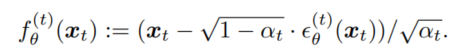
이제 generative process를 다음과 같이 정의하자. 여기서 $p_{\theta}(x_T) = N(0, I)$이다.

우리의 variational inference objective는 다음과 같다.

또한 아래 Theorem 1을 통해 다음과 같은 결론을 얻을 수 있다.

variational objective $L_{\gamma}$는 파라미터 $\theta$가 시간 $t$에 대해 공유되지 않는 경우 가중치 $\gamma$에 의존하지 않는다. 이러한 $L_{\gamma}$의 특성으로 인해 (1) DDPM에서의 objective는 $L_1$이며 (2) J_{\sigma}$의 최적 해 역시 $L_1$과 동일하다는 사실을 알 수 있다. 따라서 파라미터 $\theta$가 시간 $t$에 의해 공유되지 않으면 $J_{\sigma}$ 대신 $L_1$을 variational objective로 사용해도 무방하다. (→ DDPM과 DDIM은 동일한 목적 함수를 공유한다.)
Sampling from generalized generative process
DDIM과 DDPM은 objective function을 공유하고 있기 때문에 pretrained DDPM을 사용할 수 있으며, $\sigma$를 변경하여 샘플을 더 잘 생성하는 모델이 되게끔 학습시킬 수 있다.
앞서 정의한 $p_{\theta}(x_{1:T})$에 대해 $x_t$로 부터 $x_{t-1}$을 다음과 같은 방법으로 생성할 수 있다.

여기서 $\sigma$의 값이 달라짐에 따라 generative process가 달라지겠지만, 동일한 ${\epsilon}_{\theta}$를 사용하기 때문에 재학습시킬 필요 없다.
만약 ${\sigma}_t$의 값이 다음과 같다면, forward process는 Markovian이 되며, generative process는 DDPM이 된다.

만약 ${\sigma}_t = 0$이라면 forward process는 $x_{t-1}$와 $x_0$가 주어지면 deterministic해진다. ($t = 1$제외) generative process에서는 random noise 부분이 0이 되기 때문에, sampling 과정이 고정된다. DDIM(denoising diffusion implicit model)은 implicit probabilistic model trained with DDPM objective이기 때문에 forward process에 더 이상 diffusion이 포함되어 있지 않아도 일종의 diffusion model로서 간주된다.

이해가 안되서 gpt에게 물어본 결과!! 또한 $L_1$은 forward process의 step size나 형태에 영향을 받지 않고, $q_{\sigma}(x_t|x_0)$에 의존하므로, forward process의 step size를 T보다 작게 하여 생성 과정을 보다 빠르게 할 수 있다. $\tau$를 $[1, ..., T]$의 subsequence로 정의하여 $q(x_{{\tau}_i}|x_0) = N(\sqrt{{\alpha}_{{\tau}_i}}x_0, (1 - {\alpha}_{{\tau}_i})I)이도록 한다. generative process는 이제 reverse $\tau$에 대해 따라 샘플링을 진행하면 되는데, $\tau$의 길이가 $T$보다 매우 작게 만들어 계산의 편의성을 향상시켰다.
Relevance to neural ODE

위 식이 ODE로 생각해 아래와 같이 적을 수 있다.

여기서 $\sigma = \sqrt{1-\alpha} / \sqrt{\alpha}$, $\bar{x} = x / \sqrt{\alpha}$라고 두면 위 식은 아래의 ODE를 푸는 Euler method로 간주할 수 있다.

단, 여기서 initial condition은 $x(T) \sim N(0, \sigma(T)) $ for a very large $\sigma(T)$이다.
이는 discretization step이 충분하면 generation process를 반대로 돌려 $x_0$(data)에서 $x_T$(noise)로 encode할 수 있다는 말이다.
참고로 위와 같은 접근은 Song이 제안한 "probability flow ODE"에서도 논의되는 내용으로 위 ODE는 Song이 제안한 부분의 특수한 경우이다. (Variance - Exploding SDE와 동일) Song이 제안한 ODE와 동일한 형태이지만 샘플링 과정이 다르다는 점을 눈여겨 보아야 하는데, probability flow ODE에서는 아래와 같은 업데이트를 한다.

DDIM에서는 Euler step을 $d\sigma(t)$에 대해, Song은 $dt$에 대해 취했음을 확인하자.
Experiments
실험들에서는 DDIM이 DDPM보다 iteration을 적게 실행했을 때 월등히 좋은 성능을 보인다는 점을 입증할 것이다. 또한 DDIM는 latent space에서의 보간이 가능함을 보일 것이다. 또한 DDIM은 latent code에서 샘플을 인코딩하여 재구성할 수 있음을 보일 것이다.(DDPM은 stochastic sampling process를 가지고 있어 불가능하다.)
실험1) Sample quality and efficiency
$T = 1000, \gamma = 1$로 고정하고, $\tau$와 $\sigma$를 조정하며 실험할 것이다. 또한 $\sigma$는 아래와 같은 형태로 지정할 것이다.

여기서 $\eta$는 hyperparameter이며, DDPM에서 $\eta = 1$, DDIM에서 $\eta = 0$이다. 또한 DDPM에서 random noise가 $\sigma(1)$보다 큰 경우는 $\hat{\sigma}$로 따로 아래와 같이 정의할 것이며, CIFAR 10 샘플들에 대해서만 사용할 것이다.
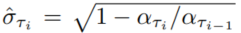
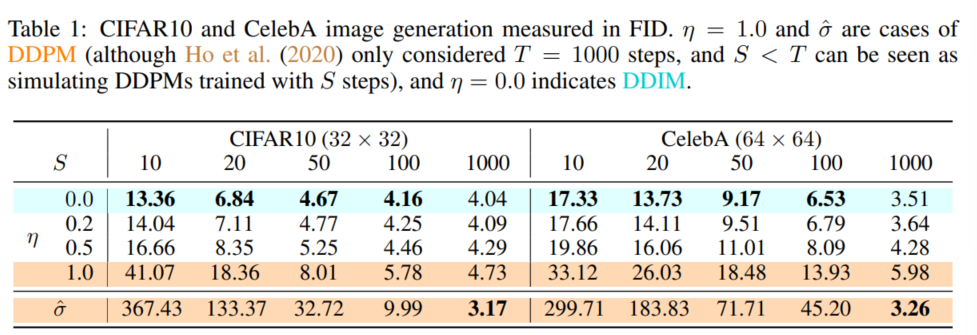

실험 결과 $dim(\tau)$가 커질수록 샘플의 퀄리티가 좋아지며, $dim(\tau)$가 작을때는 DDIM의 성능이 월등히 좋은 것을 알 수 있다. 즉, 짧은 경로로 샘플링을 할 경우 DDPM의 성능이 현저히 떨어짐을 알 수 있다.
실험2) sample consistency in DDIMS
DDIM의 샘플링 과정은 deterministic하며, $x_0$는 오직 $x_T$에만 의존한다. 아래 그림에서는 동일한 $x_T$로 시작하면서도 서로 다른 $\tau$에서 생성된 이미지를 나타낸 것으로, 작은 $\tau$(적은 iteration)에 의해 생성된 샘플과 큰 $\tau$(많은 iteration)에 의해 생성된 샘플을 비교했을 때, 세부 사항만 약간 다르다는 것을 알 수 있다. 따라서 $x_T$만으로도 이미지의 유용한 잠재 인코딩이 될 수 있으며, 샘플 품질에 영향을 미치는 세부 사항은 매개변수에 인코딩 된 것으로 보인다.

실험3) Interpolation in deterministic generative process
$x_T$에서의 보간이 유의미한 보간(semantic interpolation)을 만들어낼 수 있는지 알아본 실험으로 아래와 같이 유의미한 결과를 보여준다.

실험4) Reconstruction from latent space
DDIM이 특정 ODE의 Euler integration으로 구현되기 때문에, $x_0$에서 $x_T$로 인코딩하고, 그 결과 얻은 $x_T$에서 다시 $x_0$로 재구성할 수 있는지 확인해보고자 한다. CIFAR 10에 대해 다음 실험을 진행하고, MSE를 측정해보았다. 이 때의 $\tau$의 length를 $S$라고 뒀는데, $S$의 값이 클수록 DDIM의 reconstruction error가 더 낮아지고, Neural ODEs와 normalizing flows와 유사한 결과를 보여준다는 것을 확인할 수 있다.
Related works(DDPM, NCSN)
DDPM optimize a variational lower boind to the log-likelihood, whereas NCSNs optimize the score matching objective over a nonparametric Parzen density estimator of the data.
DDPM과 NCSN 모두 노이즈를 포함한 데이터를 점진적으로 디노이징하는 과정을 거치며, 좋은 샘플을 얻기 위해 많은 단계를 반복한다. 반면 DDIM은 $x_T$로부터 $x_0$가 deterministic하게 결정되는 암묵적 생성모델로 DDIM에서는 semantic interpolation 능력이 있다. DDIM은 variational perspective에서 도출하였으며, Langevin dynamics의 제약은 없다. 따라서 DDIM은 DDPM보다 더 적은 반복에서 더 우수한 샘플 품질을 보여준다고 할 수 있다. 또한 DDIM의 샘플링 절차는 특정 샘플링 경로와 관계없이 동일한 $x_T$로부터 유사한 높은 수준의 시각적 특징을 생성한다.
Discussion
We have presented DDIMs – an implicit generative model trained with denoising auto-encoding / score matching objectives – from a purely variational perspective. DDIM is able to generate high quality samples much more efficiently than existing DDPMs and NCSNs, with the ability to perform meaningful interpolation from the latent space. The non-Markovian forward process presented here seems to suggest continuous forward processes other than Gaussian (which cannot be done in the original diffusion framework, since Gaussian is the only stable distribution with finite variance). We also demonstrated a discrete case with a multinomial forward process in Appendix A, and it would be interesting to investigate similar alternatives for other combinatorial structures.
Moreover, since the sampling procedure of DDIMs is similar to that of an neural ODE, it would be interesting to see if methods that decrease the discretization error in ODEs, including multistep methods such as Adams-Bashforth, could be helpful for further improving sample quality in fewer steps. It is also relevant to investigate whether DDIMs exhibit other properties of existing implicit models.
Reference
https://junia3.github.io/blog/ddim
Welcome to JunYoung's blog | DDIM(Denoising Diffusion Implicit Models) 이해하기
들어가며 … DDPM은 adversarial training과 같이 직접 latent prior를 지정해줄 수 없는 GAN 모델과는 다르게 collapse가 발생하지 않고 안정적인 학습이 가능하다는 장점을 통해 generative model의 새로운 기대
junia3.github.io
'논문 리뷰 > Generative Model' 카테고리의 다른 글
LDM 논문 리뷰(High-Resolution Image Synthesis with Latent Diffusion Models) (1) 2024.08.19 Attention is all you need 논문 리뷰 포스팅 리스트 (5) 2024.08.16 DDPM 논문 리뷰(Denoising Diffusion Probabilistic Models) (0) 2024.08.09 Deep Unsupervised Learning using Nonequilibrium Thermodynamics 논문 리뷰 (3) 2024.08.06 Inception Score이란? Improved Techniques for Traning GANs 논문 리뷰 (0) 2024.08.05